- 2019/07/19 시나리오 정의서에 의한 테이블 작성 & 시퀀스2019년 07월 22일
- 조별하
- 작성자
- 2019.07.22.:57
[전 수업] 테이블에서 제약조건을 추가하여 어떠한 상황에서 오류가 나는지 확인해 보았다.
[본 수업]시나리오 정의서에 따라 테이블을 작성을 해보자
※우리가 평상시에 입력하던 데이터 자료나 형태를 액셀을 이용하여 먼저 설계를 하고 테이블을 작성한다
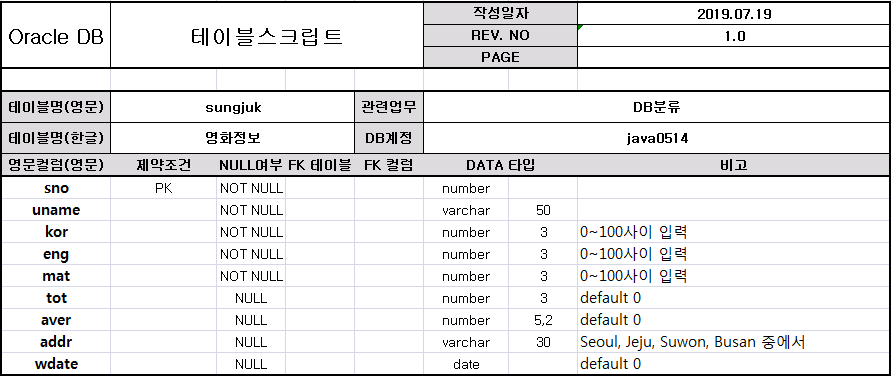
1. 테이블 정의서에 맞게 코딩하기
create table sungjuk( sno number primary key ,uname varchar(50) not null ,kor number(3) check(kor between 0 and 100) ,eng number(3) check(eng between 0 and 100) ,mat number(3) check(mat between 0 and 100) ,tot number(3) default 0 ,aver number(5,2) default 0 ,addr varchar(30) check(addr in('Seoul','Jeju','Suwon','Busan')) ,wdate date default sysdate );2. default 칼럼에 데이터가 입력되지 않은경우 자동으로 입력
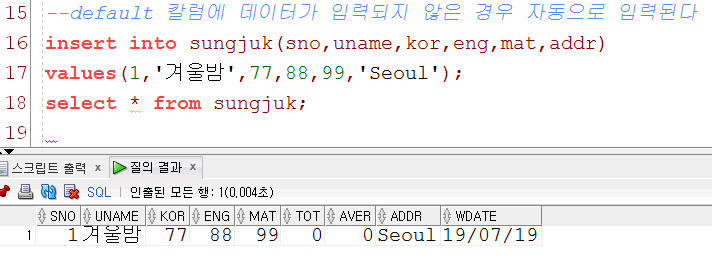
tot나 aver를 넣지 않았는데 0값이 자동으로 입력 ※default 값을 0으로 설정해 주었기 때문에 데이터를 insert해주지 않아도 0이라는 데이터가 들어갔다
...더보기3. [시퀀스]란
1) 정의: 연속적인 숫자값을 자동으로 증가시키는 숫자를 발생시키는객체
2) 생성create sequence 시퀀스 이름
[increment by 숫자]
[start with 숫자]
[maxvalue 숫자]
[minvalue 숫자]
[cycle | nocycle] --일련번호 순환여부
[cache | nocache] --빠른처리를 위해 시퀀스의 값을 메모
--서버를 껐다 켜지면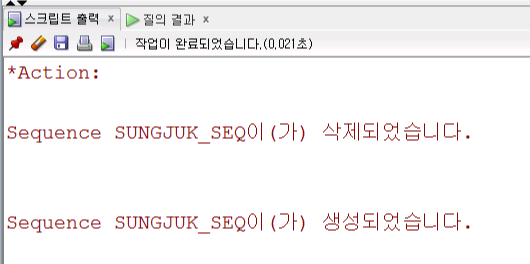
--시퀀스 생성& 삭제 해 보기
drop sequence sungjuk_seq; create sequence sungjuk_seq increment by 1 --증가값 start with 103 --시작값 maxvalue 1000000000 --최대값 nocycle --사이클 x nocache --캐쉬 x3) 시퀀스 호출함수
주의:시퀀스 생성 후 nextval을 호출해야 시퀀스에 초기값이 설정됨
nextval :다음값을 반환함. 다음번호 발금
select sungjuk_seq.nextval from dual;
currval :현재값을 반환함. 최근발금된 번호
select sungjuk_seq.currval from dual;4) 서브쿼리를 이용한 일련번호 발급
주의:시퀀스와 혼합해서 사용하지 않도록 주의- 시퀀스 문제
c_emp 테이블에 데이터 입력시 sequence를 이용해서 id를 입력하도록
206에서 시작하여 1씩 증가되고,최대값은 999로 설정하여 시퀀스르 생성하시오
시퀀스 이름 c_emp_seq
create sequence c_emp_seq increment by 1 --증가값 start with 206 --시작값 maxvalue 999 --최대값※시퀀스 목록 조회

select*from USER_OBJECTS where OBJECT_TYPE='SEQUENCE';5) null값을 포함하는 컬럼을 특정한 값으로 전환하는 함수
형식:nvl(null값을 포함하고있는 컬럼이나 식 전환하고자하는 목표값)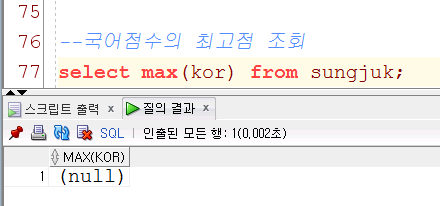
국어점수의 최고점 조회
select max(kor) from sungjuk;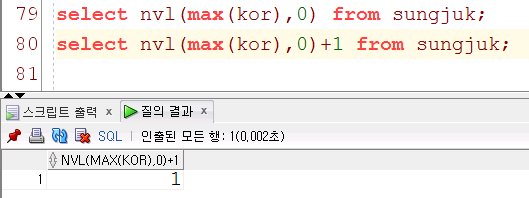
null값이 나오면 0으로 바꿈
select nvl(max(kor),0) from sungjuk;6) distinct를 이용한 중복데이터 없애기
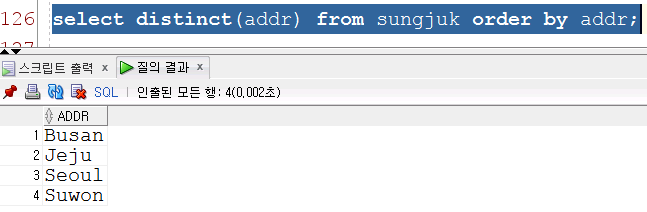
select distinct(addr) from sungjuk order by addr desc;7) GROUP BY
칼럼에 동일 내용끼리 그룹화 시킴
형식)group by 칼럼명1,칼럼명2,,~~~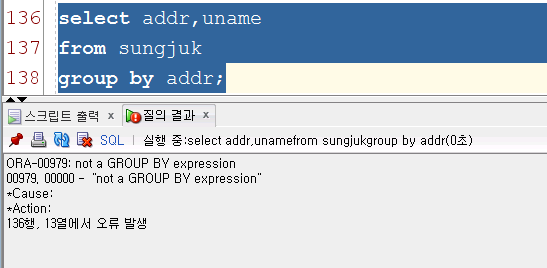
select addr,uname from sungjuk group by addr;※오류 -group by에 의한 결과값이 오로지 1개만
-존재하는 값만 조회할수 있다
-집계함수와 많이 사용한다(빅데이터에서 많이 사용되어 진다)8) 집계함수

select count(*),--레코드 갯수 sum(kor),--국어점수 합계 avg(eng),--영어점수 평균 max(mat),--수학점수 최고점 min(tot)--총점 최저점 from sungjuk;※문1)

인원수 조회 select addr,count(*) from sungjuk group by addr order by addr;※문2

select addr,round(avg(kor),2)as 국어점수 from sungjuk group by addr order by avg(kor) desc;※문3

select addr, max(kor),max(eng),max(mat) from sungjuk group by addr order by addr;4. 2차 그룹핑
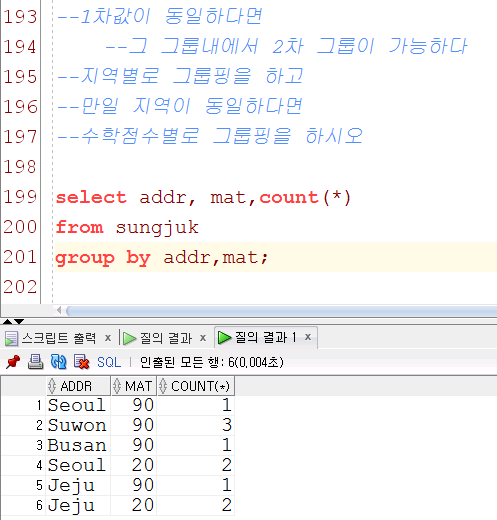
select addr, mat,count(*) from sungjuk group by addr,mat order by addr;'JAVA 교육 > Sql' 카테고리의 다른 글
2019/07/23 Group by 명령어 & 서브쿼리 (0) 2019.07.24 2019/07/22 오라클 함수 (0) 2019.07.24 2019/07/22 SQL 활용 연습문제 (0) 2019.07.22 2019/07/19-DB (제약조건) (0) 2019.07.19 2019/07/19-SQL (sqldeveloper를 이용한 DB) (1) 2019.07.19 다음글이전글이전 글이 없습니다.댓글